The Site Crawler is a powerful tool that lets you deeply explore your WordPress website and update a Knowledge Base for your Chatbots to use during conversation using the AI RAG technique (Retrieval Augmented Regeneration). OpenAI Embeddings are created in the Knowledge Base for all new or updated crawled content sources.
Note: no Knowledge Base entries are deleted as part of the Site Crawl process, you will need to use the Knowledge Management feature to delete old KB entries.
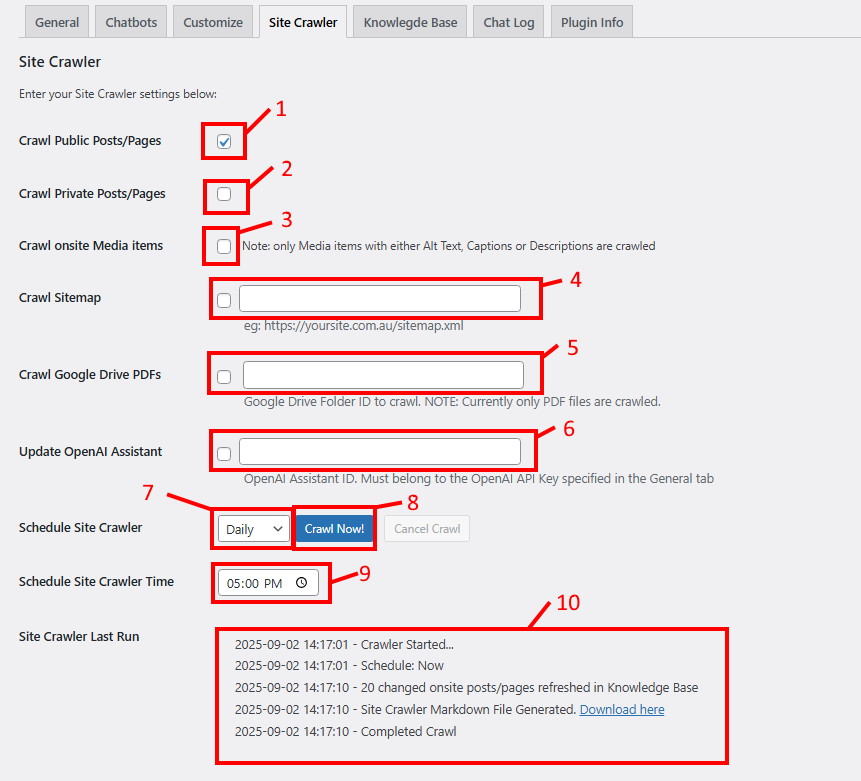
- 1 – Crawl Public Posts/Pages: Check this ON if you want the Site Crawler to crawl the content within all your public pages and posts on your website.
- 2 – Crawl Private Posts/Pages: Check this ON if you want to crawl private pages and posts. This is useful if you want to create specific content that is usable by the Chatbot(s) but not visible on the public web as a page or post.
- 3 – Crawl Onsite Media Items: Check this ON if you want your Image Library to be included in your Sources that Chatbot(s) may present to the user. Note: only Media Items with either Alt Text, Captions, or Descriptions are crawled. We recommend you revisit your image library and enter meaningful information into any of these fields if you wish that media item to be presented by the Chatbot.
- 4 – Crawl Sitemap: (Pro Plan only). Check this ON and enter a URL to an XML sitemap that you want the Site Crawler to crawl. This allows maximum control over what pages/posts are included (or excluded) in the Knowledge Base. It also allows you to bring in content from other websites you own and stores their URLs in your Knowledge Base for Chatbots to use.
- Note: A Sitemap containing other Sitemaps is allowed, but only 1 level down is traversed, ie: if those children Sitemaps contain Sitemaps themselves, then the Grandchildren Sitemaps will be ignored. Clear as mud? 🙂
- 5 – Crawl Google Drive PDFs: (Pro Plan only). Check this ON and enter a valid shared Google Drive folder ID and have the Site Crawler crawl PDF’s in that location. Each page of the PDF is brought into a separate entry in the Knowledge Base with ‘gdrive_{filename}_page{N}’ as the source.
- Note: you also need to have a valid Google API Key in the General Settings tab to use this feature.
- 6 – Update OpenAI Assistant: If some of your Chatbots use an OpenAI Assistant for knowledge, you can update the Assistant with the Site Crawler results by checking this setting ON and entering a valid OpenAI Assistant ID (Note: it must belong the the OpenAI API Key entered in the General Settings tab or an error will result). The Site Crawler will then upload the Markdown file generated from the Crawl (see below #10) to the Assistant. It will be named “twxchat-sitecrawl.md” in the OpenAI Assistants console.
- Update: This feature will likely be replaced in the near future as the “OpenAI Assistants API” is being deprecated and replaced by another API. If this is similar functionality we will likely adopt it in TWX-Chat.
- 7 – Schedule Site Crawler: Schedule the Site Crawler to run ‘Daily’, ‘Weekly’ or ‘Select’. ‘Select’ means: only as required, ie: using the Crawl Now button below. Depending on which Schedule you choose you will need to select the desired Day and/or Time the Site Crawler will run (see #9 below). It uses the WordPress CRON functions to schedule this event and will have a CRON job name similar to ‘twx_chat_site_crawler_XXX_event’.
- 8 – Crawl Now button: Click this button to execute the Site Crawl immediately in the background. If the button is disabled it is either because the Site Crawler is running currently or you need to save some changes first. A ‘Cancel Crawl’ button will appear whilst the Site Crawler is running which requests the Crawl to abort. The Crawl Progress area (#10 below) will be refreshed every few seconds with updates on the Crawl. You can navigate to other pages safely whilst the Crawl runs. The ‘Crawl Now’ button will re-enable once it is completed.
- Note: Once complete, feel free to check the Knowledge Base to see if the Site Crawl has correctly populated entries.
- 9 – Daily / Weekly Schedule: As per #7 Above, you will need to select the desired Day and/or Time the Site Crawler will run if you wish to Schedule the Site Crawler.
- 10 – Site Crawler Last Run / Crawl Progress area: This space shows either the progress of the currently running Site Crawl or the results of the last Site Crawl that occurred (eg: maybe from a Scheduled Crawl). It notifies the Admin of dates/times, number of sources refreshed/added into the Knowledge Base and also provides a link to a Markdown file that was generated as part of the process. It includes all crawled content, not just new or refreshed content. This markdown file can be downloaded for your own purposes or even uploaded into another WordPress site running TWX-Chat (see Knowledge Base tab, item #6).